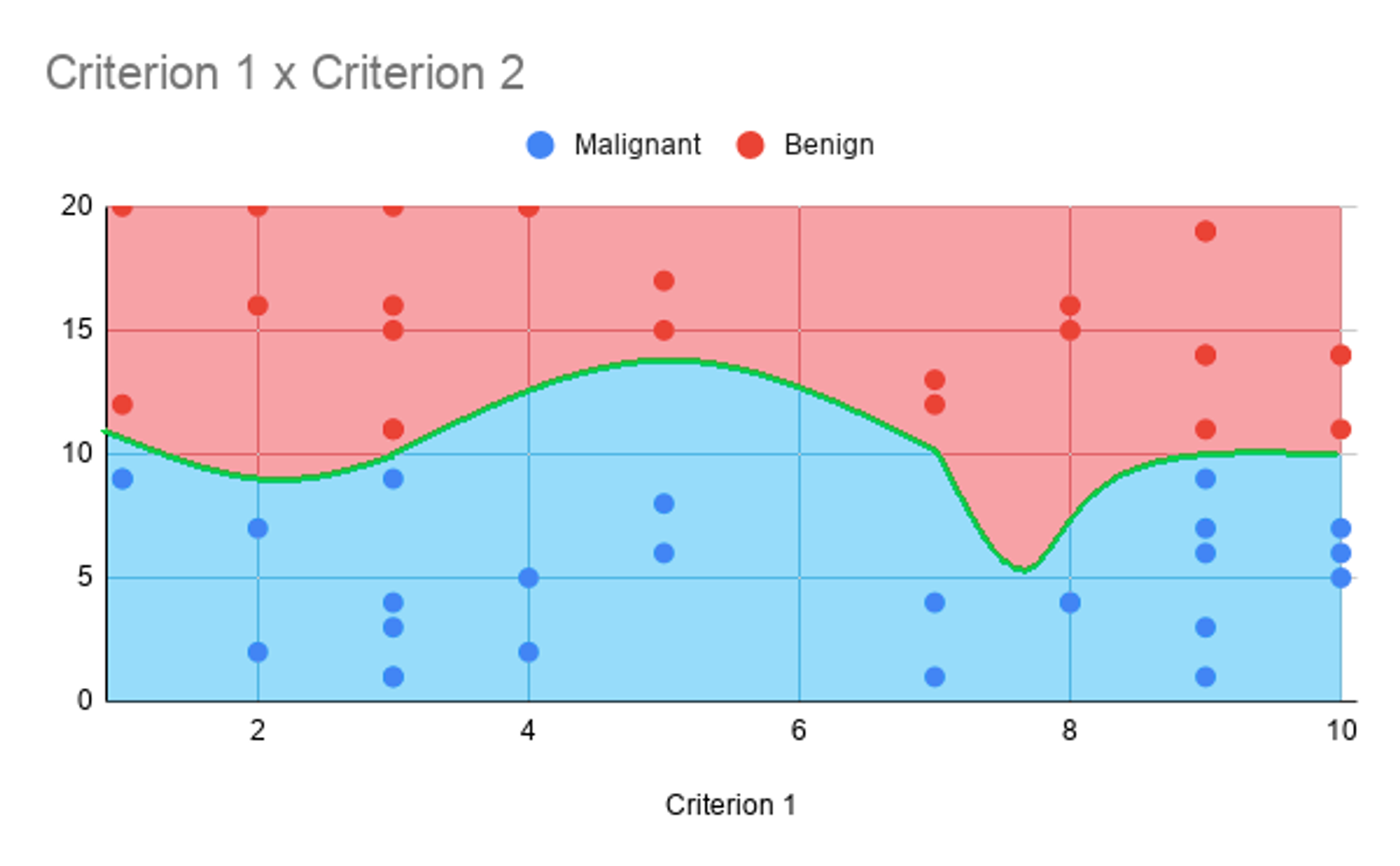
Fitting Decision Boundaries to a Data Set
This is a very specific art, that varies from algorithm to algorithm. Nevertheless, the general principle of fitting a decision boundary to data is to find the line/curve that splits the data in a way that the least amount of data is put in the wrong category. This is analogous to the concept of the Cost Function, which plays a slightly different, but also somewhat similar role as in Regression.
As with Regression, the cost function will vary between Classification Algorithms, but the idea is the same. In the next chapter, we will begin with our first Classification Algorithm - Logistic Regression.
Previous Section
1.2 Introduction to Decision BoundariesCopyright © 2021 Code 4 Tomorrow. All rights reserved.
The code in this course is licensed under the MIT License.
If you would like to use content from any of our courses, you must obtain our explicit written permission and provide credit. Please contact classes@code4tomorrow.org for inquiries.