Consider the tract of land you live on. In one sense, the Earth is but one mass, filled with mountains and valleys, rivers and oceans and creatures. But we don't think of all land the same way. We divide it into continents, countries, states, cities, towns, houses and rooms. How then can you tell if, say, your sister’s shoes are in your room? Well, you draw a line — you define a boundary. This is much the way countries, cities or towns understand their own territory, and is a very common phenomenon.

As it happens, this is also the way a classification algorithm differentiates between different classes or groups of examples. Let’s think about this in the context of the Supervised Learning model:
First, we get our data, just as we did with Regression:

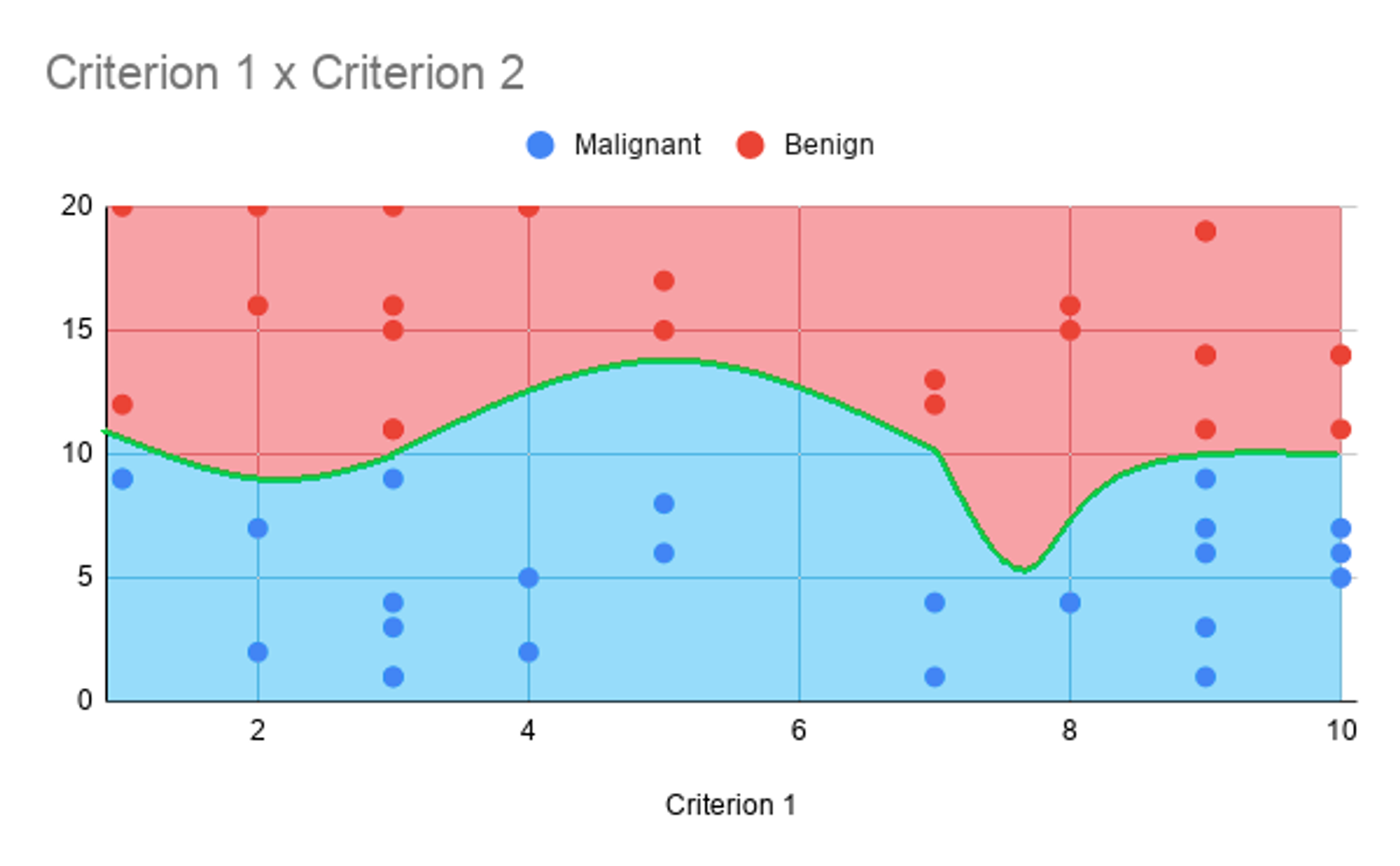
Then, we train the algorithm to create what’s called a decision boundary. This is basically a line or curve that lies between the regions of various groups, graphically. Here’s what one looks like:

The decision boundary helps us decide which class or group a particular example belongs to. For example, here, we could say that all examples who have a store rating greater than 3 are considered good stores, while all others fall in a medium category. This is a very simple decision boundary, being just a flat line. Often Machine Learning can produce more complicated decision boundaries, which is really the advantage of the method. But in any case, we will get to that in future chapters.
As you can see, however, the process of fitting a decision boundary is quite similar to that of fitting a curve in regression. Perhaps the difference is that regression attempts to fit a curve that follows the data, while classification tries to derive the ideal boundary between groups of examples. That is, in some ways, an oversimplification, but it is important to be able to draw these connections amongst the various disciplines of Machine Learning.
Copyright © 2021 Code 4 Tomorrow. All rights reserved.
The code in this course is licensed under the MIT License.
If you would like to use content from any of our courses, you must obtain our explicit written permission and provide credit. Please contact classes@code4tomorrow.org for inquiries.