Just like with logistic regression, K-Nearest Neighbors (or KNN) is a machine learning model that can solve classification problems. It stores all available data points and classifies new data based on a similarity measure. To classify a new data point, the algorithm compares it with its closest neighbors.
For example, let's say we're trying to predict whether a customer will want a medium size T-shirt or a large size T-shirt given their height and weight. Here is a graph of our existing data, where blue dots represent customers that wear medium size T-shirts and orange dots represent customers that wear large size T-shirts:
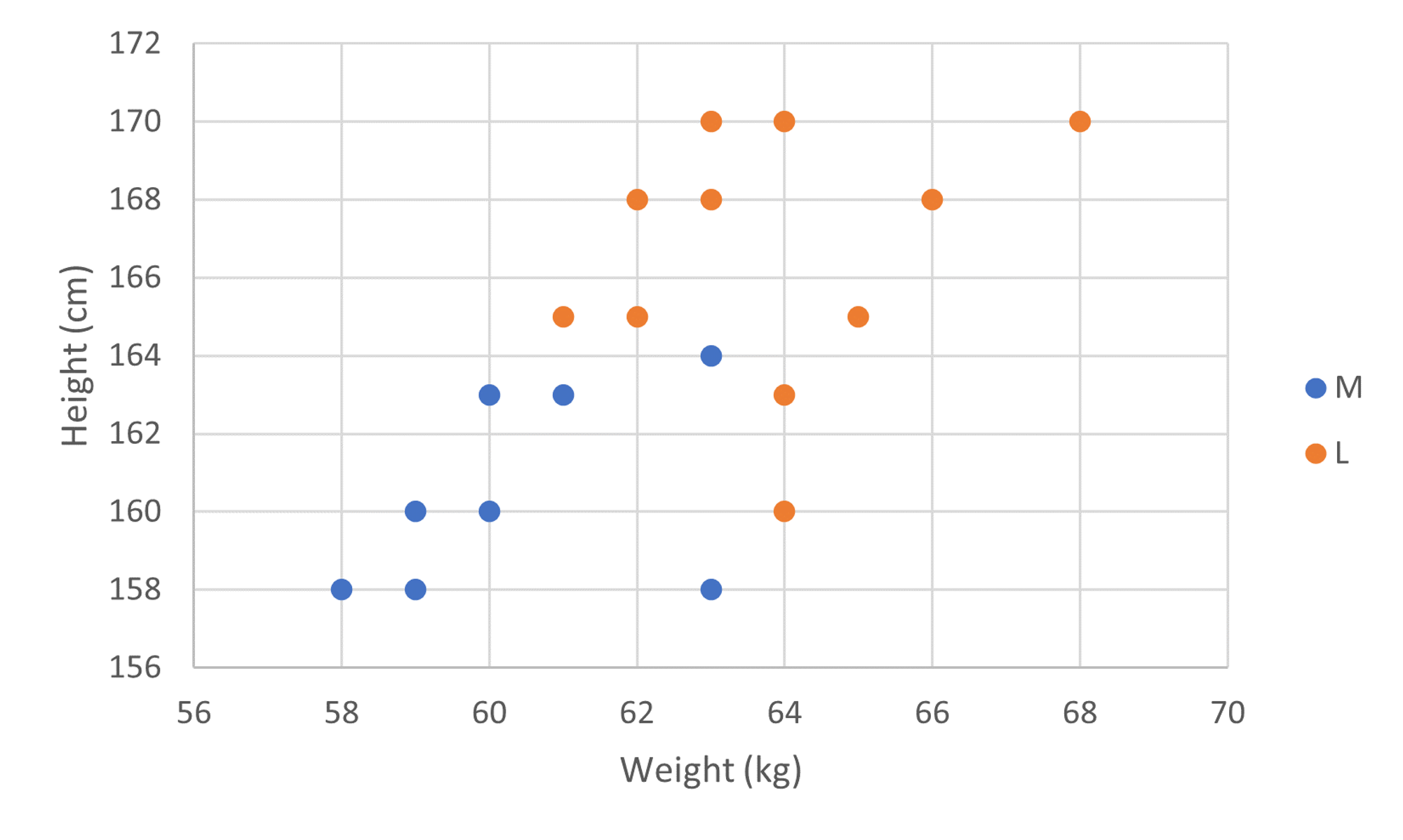
Given this data, how can we predict the T-shirt size of a new customer given their height and weight?
Approach 1: Nearest Neighbor
One approach is to find the nearest neighbor to our new customer, or an existing data point that is the closest to the new customer. Then, we classify the new customer with the same label as that of its nearest neighbor.
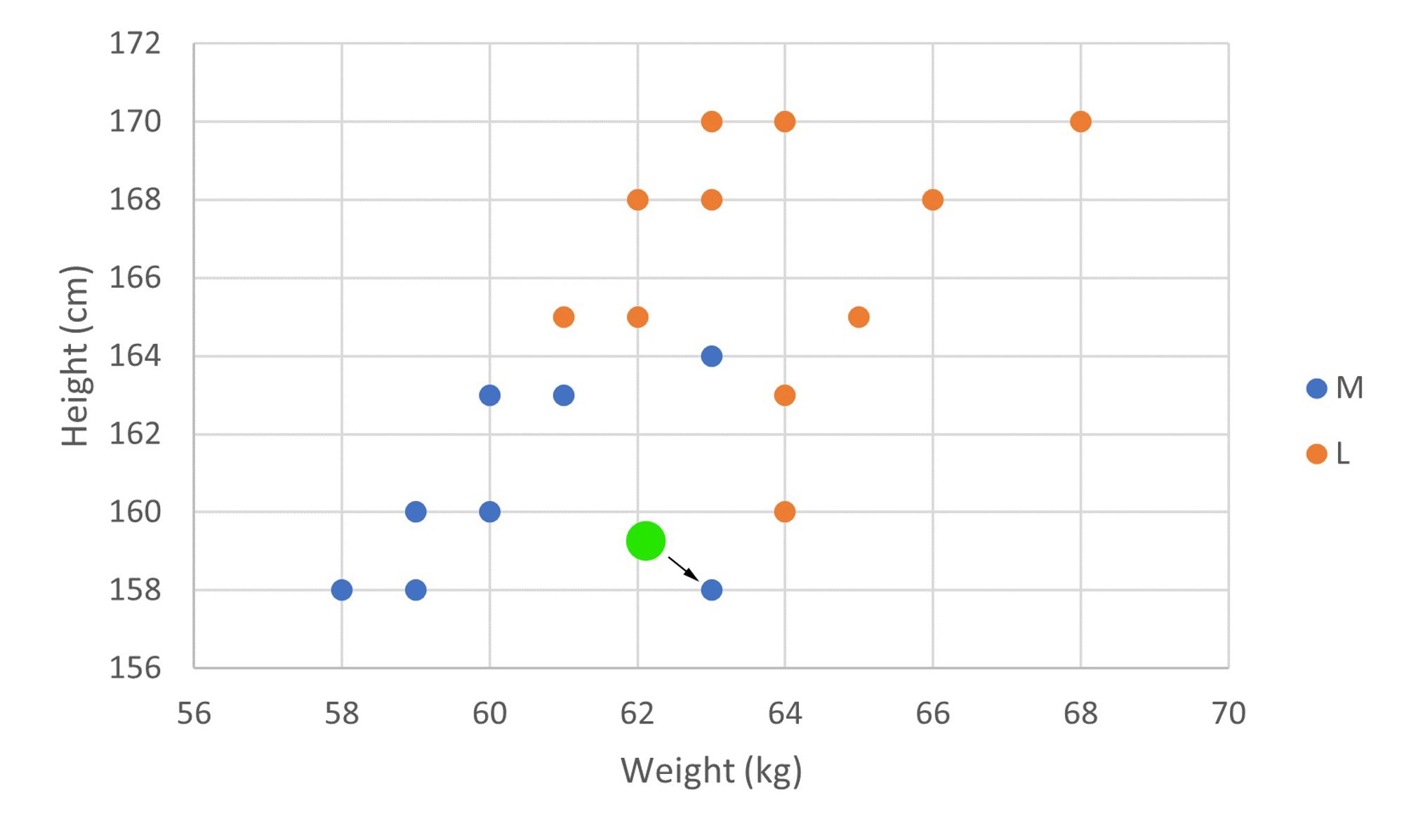
For example, if our new customer is the green data point, its nearest neighbor would be the data point it's pointing to. Since that customer wears medium size T-shirts, we would classify the new customer as also wearing medium size T-shirts.
Now while the nearest neighbor approach works well in this example, it is very susceptible to outliers.
.jpg?table=block&id=de788344-e2f2-4c78-a15e-bf60d975d463&cache=v2)
In this example, while we would probably expect the new customer to wear large size T-shirts, because of one medium T-shirt outlier, our nearest neighbor algorithm would classify the new customer as wearing medium T-shirts.
Approach 2: K-Nearest Neighbors
Instead of looking at the one closest point to a data point we're trying to classify, K-Nearest Neighbors will look at the closest points, where can be any natural number . Then, we classify the new data point with whichever label is the most common in our set of points. By looking at multiple points to classify a new data point, our algorithm is a lot less susceptible to outliers. Let's revisit the previous example where our Nearest Neighbor approach failed, but this time we use KNN with .
.jpg?table=block&id=84a51ff2-f72d-46fa-a5ce-67485dc55095&cache=v2)
Here, we would classify the new customer as wearing large size T-shirts because that's the most common label among the new customer's five "nearest neighbors," thus overcoming the problem with outliers. Although we arbitrarily chose in this example, can equal anything, so choosing the best value for is very important for KNN to work effectively.
Next Section
3.2 Important Optimization TechniquesCopyright © 2021 Code 4 Tomorrow. All rights reserved.
The code in this course is licensed under the MIT License.
If you would like to use content from any of our courses, you must obtain our explicit written permission and provide credit. Please contact classes@code4tomorrow.org for inquiries.