Concepts
Before we look at the algorithm, let us consider the three main symbols we use in the decision tree diagram. You will not need to remember their names to be able to use Decision Trees in your programming, but they will help us understand the concept clearly.
Here’s an example of a decision tree, just so you can compare with what we are going to discuss.
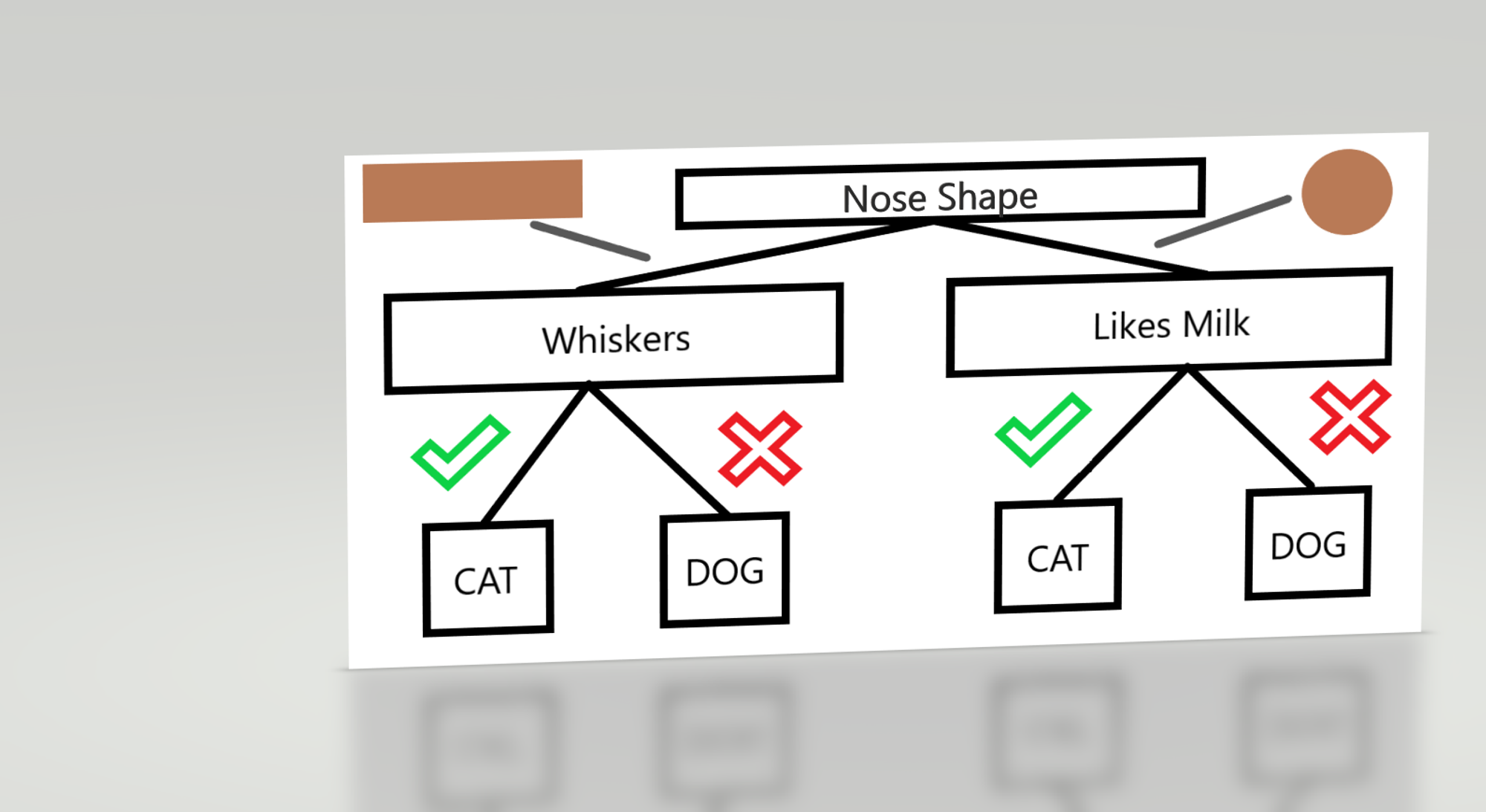
Decision Trees are split into what are called nodes. In effect, each internal node represents a test.
The arrangement and connections of these internal nodes are what we’ll be training our algorithm to optimize. The internal node represents a test. For example, in a decision tree analyzing Cat or Dog Pictures, the first internal node, labelled “Nose Shape”, tests whether a particular animal has a circular or rectangular nose.
If the data reveals that the animal has a circular nose, a black line leads the example to another test. This line is the representation of what is called a branch. Each branch refers to a specific result of the test - square nose or circular nose, here.
Let's say that the first test yields the result that the animal has a rectangular nose, the diagram leads to what is called a leaf node, which results in an output class. This means assigning the example animal some class - here, a dog, perhaps.
As we have seen so far in your study of Classification algorithms, training the algorithm means that we try to make as many of our predictions accurate. In Decision Trees, this concept is referred to as ‘Node Purity’. Naturally, what we aim for is that we gain the greatest node purity, meaning that data that follows the chain of tests from internal nodes, is most often classified as the correct class.
This is a little bit more of a conceptual algorithm than some of the others we have studied before, so pay close attention to the following two concepts. Of course, these are not required for implementation, but it is always very useful to have a clear understanding of how Decision Trees work.
Previous Section
5.1 IntroductionNext Section
5.3 Entropy and Information GainCopyright © 2021 Code 4 Tomorrow. All rights reserved.
The code in this course is licensed under the MIT License.
If you would like to use content from any of our courses, you must obtain our explicit written permission and provide credit. Please contact classes@code4tomorrow.org for inquiries.