
Logistic Regression
Instead of creating a line of best fit to the data, logistic regression fits a different function to the data. This function is called the logistic function. Here is its equation for a single variable:
If you know calculus, you are probably somewhat familiar with this function. If not, that's totally fine. The two key parameters for this function are and , where will shift the function left/right and will scale the function horizontally. Here is what the logistic function for and looks like:
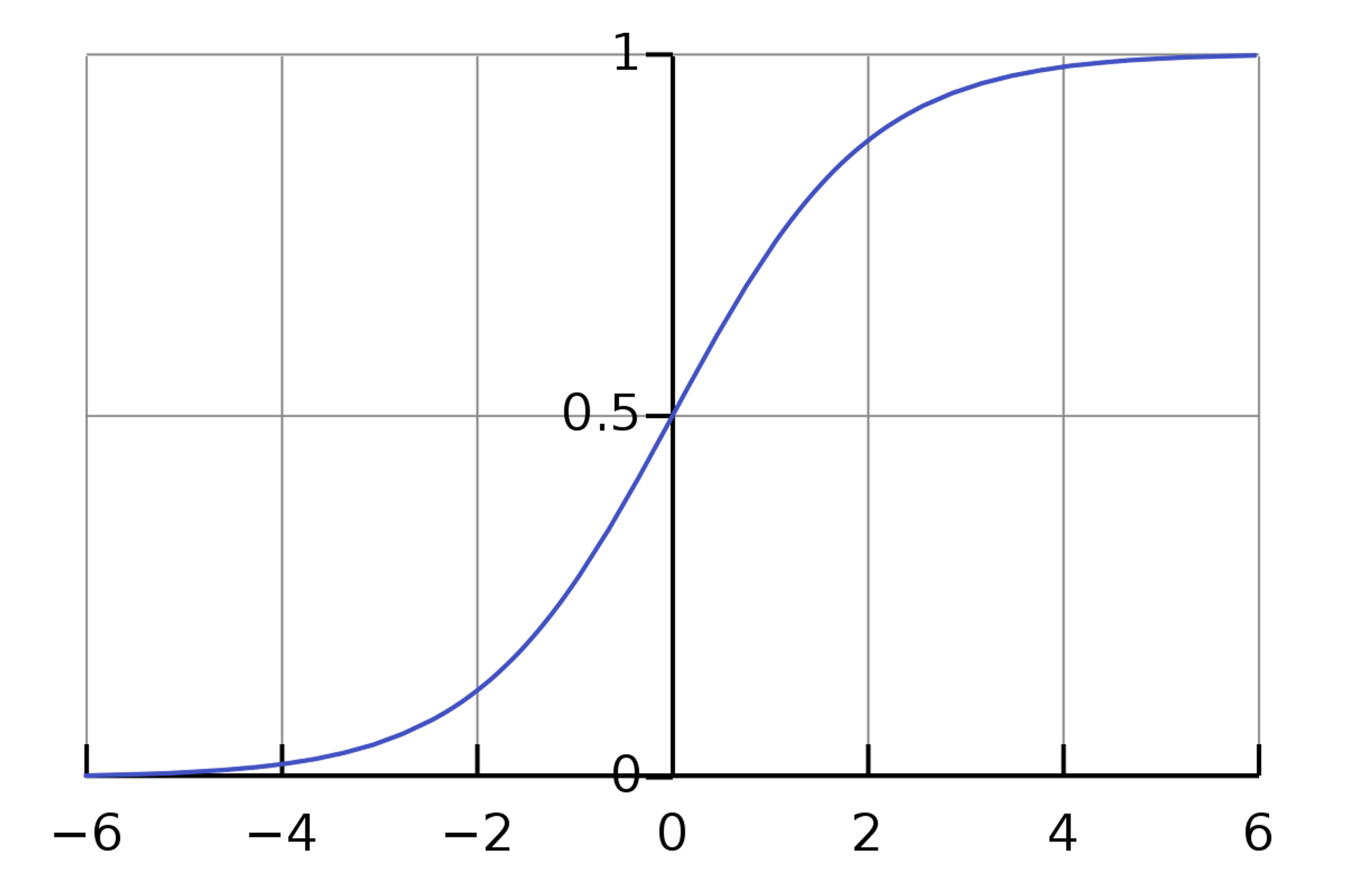
Notice how the the range of values that this function produces are all between 0 and 1, and even for really big values the function will never drop below 0 or exceed 1. This makes the logistic function a great choice for classification, as we can treat the output of the function as a probability that the output is 1. For example, an output of 0.6 gives us a 60% probability that our output is 1. Let's try fitting the logistic function to our original data on tumors.
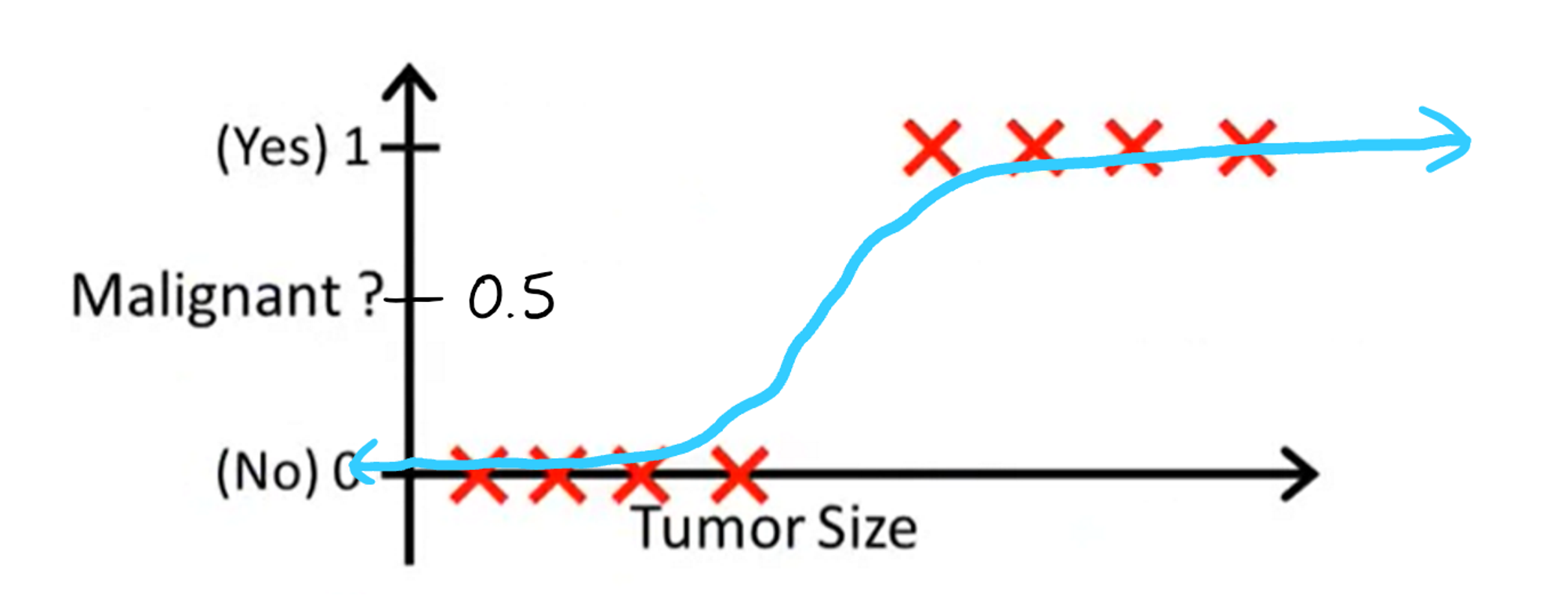
We will use the logistic function to make classifications in the same way as the linear function: if the y-value of the curve is greater than 0.5 at a given tumor size, we classify the tumor as malignant. Otherwise, we classify the tumor as benign. This also makes sense on a probability level. We would probably want to output malignant if the chance for the tumor to be malignant is greater than 50%, and benign if that chance is lower than 50%
With this model, our decision boundary would look something like this:
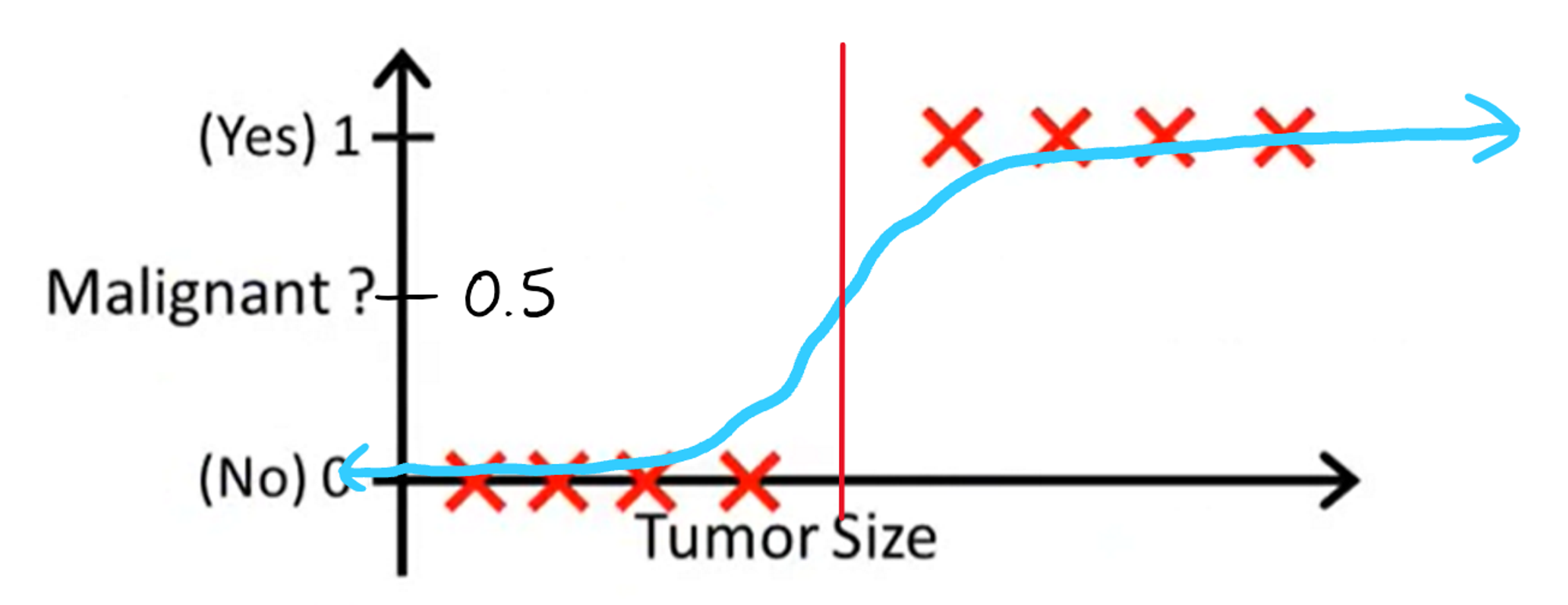
Great, this is a very reasonable decision boundary, and it turns out to be the exact same as what linear regression produced originally. Now, let's see what happens when we add back the point that messed up linear regression.
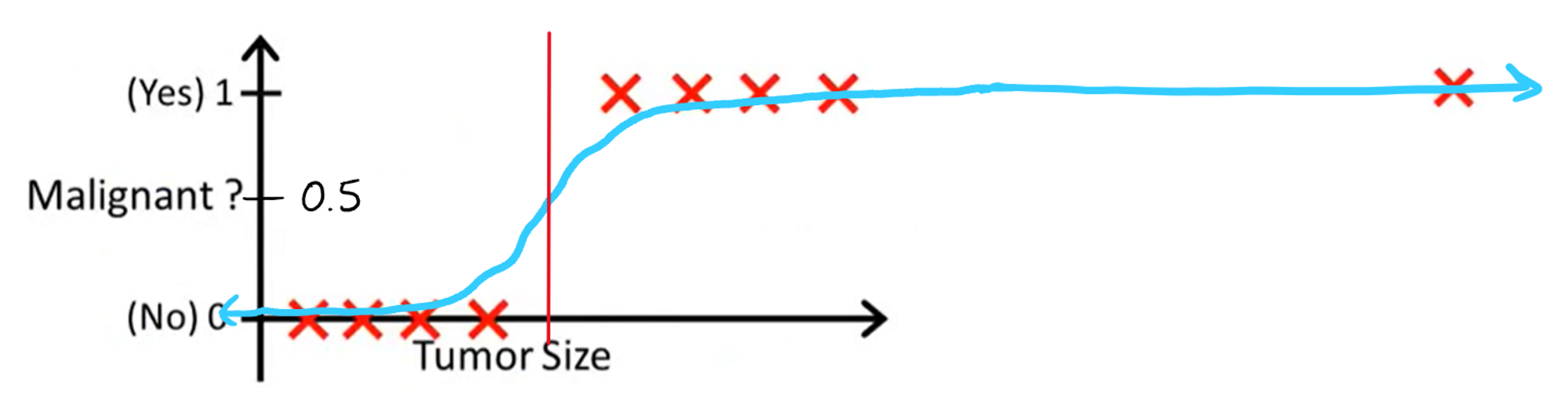
It seems like the decision boundary hasn't changed at all, which is a great sign. It turns out that logistic regression is able to completely overcome the hurdle that linear regression faced, and that no matter how many points you add that correspond with the decision boundary, the function will stay virtually the same.
Nice! We've just derived one of the most powerful algorithms for classification. This idea of fitting the logistic function to our data is preserved for higher dimensional data with more than one feature. All that changes is that there are a lot more parameters:
Fortunately, we won't have to deal with any of this complicated math when we actually use logistic regression, as that will all be done behind the scenes by scikitlearn.
Previous Section
2.1 Classification with Linear RegressionNext Section
2.3 ImplementationCopyright © 2021 Code 4 Tomorrow. All rights reserved.
The code in this course is licensed under the MIT License.
If you would like to use content from any of our courses, you must obtain our explicit written permission and provide credit. Please contact classes@code4tomorrow.org for inquiries.