With supervised learning, the prediction equation is an important step required to perform both training and testing. So let's dive into it!
Vectorization
First of all, we have to consider vectorization, an important technique used to significantly speed up calculations. This is the standard practice in Machine Learning, and you should at least theoretically understand how it works.
Vectorization just means that the lists of features and parameters will be represented as matrices. For example, if we had the following features when trying to predict the price of a house:

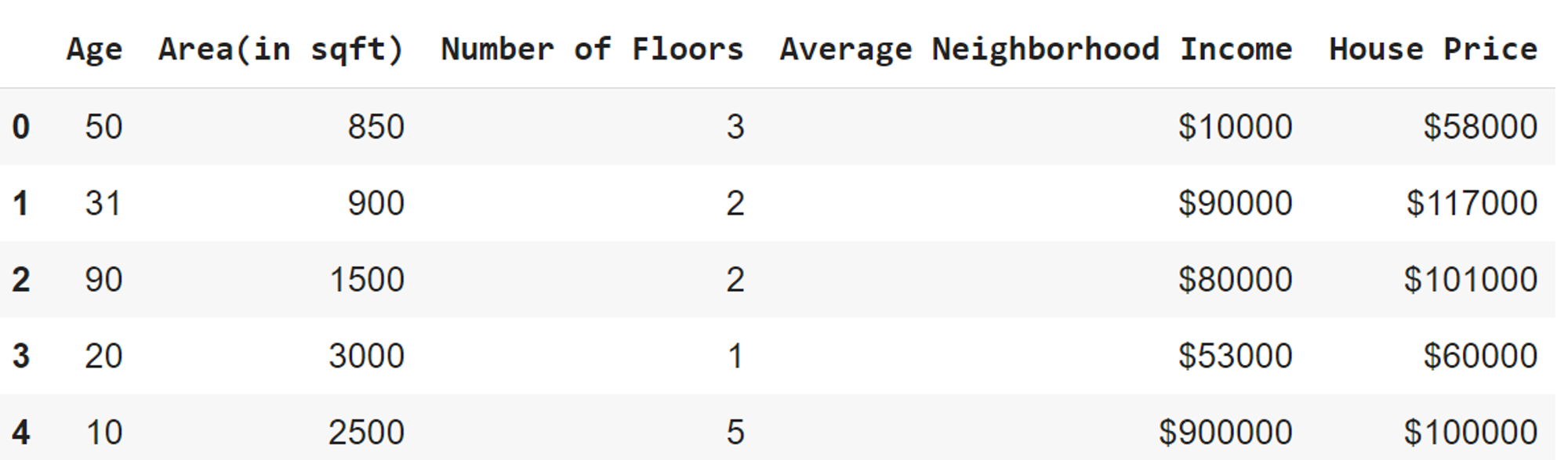
We would write this as a matrix , called the feature matrix, where the columns are various features, and the rows are different examples/observations. Similarly, we have a weight parameter assigned to each feature. We would put all of these parameters together in a vector called .
The Prediction Equation
Given that the vector represents the predictions of the ML model for each input, it is clear that some combination between and produces . Before we decide what operation this is, let's consider the dimensions of and .
The matrix has rows and columns, where is the number of observations or examples, and is the number of features.
The vector has rows and 1 column. Each row contains the weight for the corresponding feature .
Therefore, by performing the matrix multiplication , we multiply our transposed weights (which just transforms into a vector with 1 row and columns) by the feature values. We have to transpose so that we are able to multiply it with . This produces the model's predictions, which we can then evaluate or improve on, depending on what stage of the ML process we are on.
Before we continue, however, it is critical that we emphasize the difference between the prediction and the actual value. In the training stage, we try to change the parameters so as to minimize the difference between these two. But in the testing stage, we simply compare their difference, and use it as a measure of their accuracy. The actual value is data from the real world, while the prediction is the model's own creation.
Copyright © 2021 Code 4 Tomorrow. All rights reserved.
The code in this course is licensed under the MIT License.
If you would like to use content from any of our courses, you must obtain our explicit written permission and provide credit. Please contact classes@code4tomorrow.org for inquiries.