OverfittingUnderfitting Measures against Overfitting 1. Take Less Data2. Regularization3. Train/Test Data
Overfitting and Underfitting are serious problems in Machine Learning models, and how we handle with the data will be important to dealing with them.
Overfitting
Overfitting means that the ML model created is not easily generalizable. This means that while the model often does very well on the data you're training on, it's terrible with new data. This would be like thinking that all Math teachers must be 31 years old, must have a green pencil, and must have a Windows Laptop to be good at Math just because your teacher -- who is your entire training data set — fulfills these requirements. It's just not generalizable.
Often, this is a product of overcomplicated equations that fit the curve too closely to the data. Here's what it could look like:
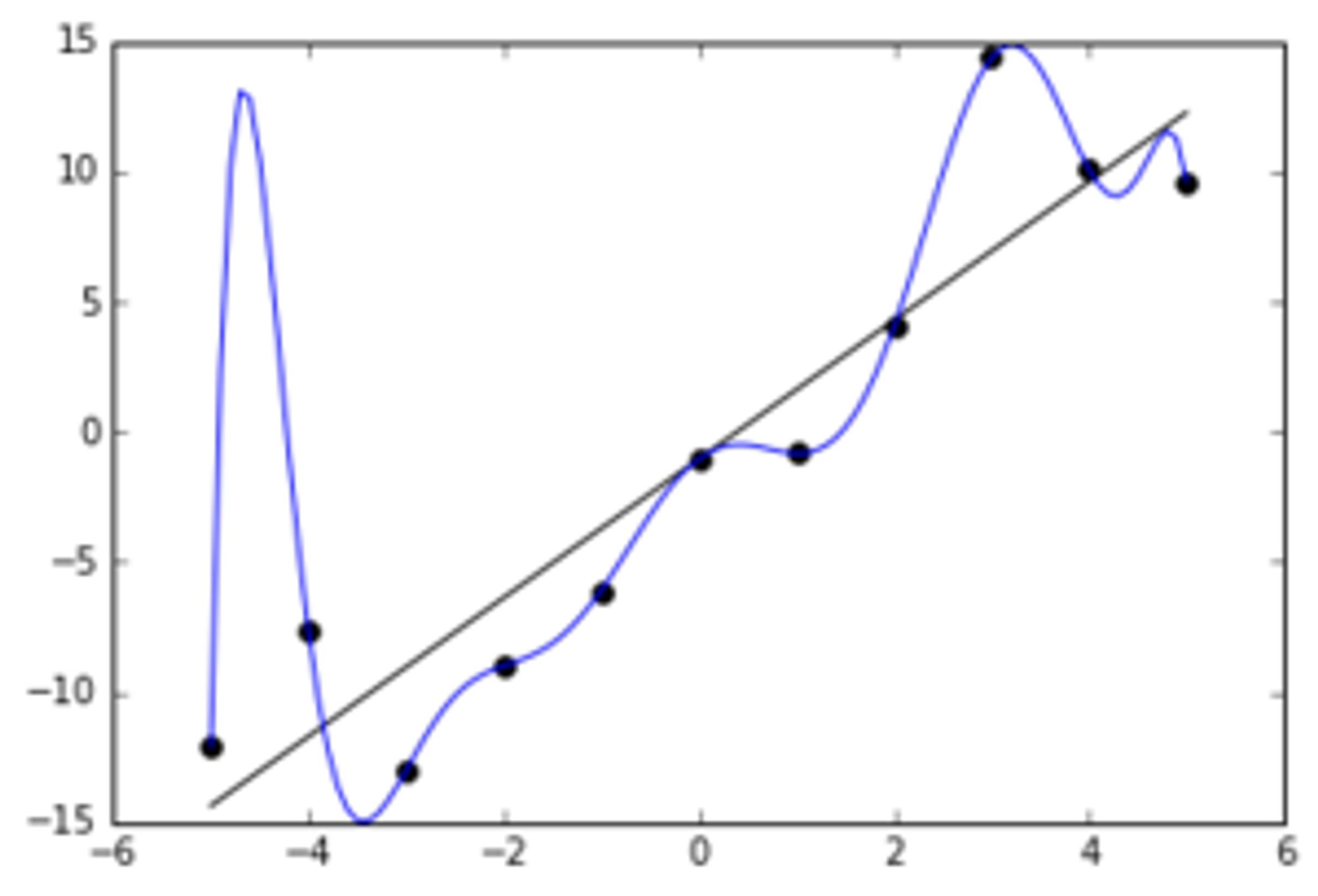
As you can see, the model here is missing the overall linear-ish trend, and instead fits a very un-generalizeable function to the data.
Meanwhile, let's discuss Underfitting.
Underfitting
Underfitting means that the ML model is too general, in the sense that it learns very little from the training data. This means the model does poorly on both training and testing data. This would be like thinking all human beings should be good at Calculus - even 3 year olds - because that's the level of detail that you could observe about your Math Teacher.
This is usually a product of an oversimplified equation - like trying to fit a straight line to clearly exponential data.
Measures against Overfitting
1. Take Less Data
By reducing the amount of data we're dealing with, we allow the curve/model to be fitted better to the data, such that it is more generalizable. If we are trying to combat Underfitting, we just do the opposite - it's like taking more data, or spending more time around Math teachers so that you are more likely to note that they tend to have a Math-related Degree.
2. Regularization
Regularization is a corrective process, essentially. Regularization effectively reduces the importance of each feature from the data by reducing the parameters that dictate the weight of each piece of information. If you regularize too heavily, you may become susceptible to underfitting, however, so watch out!
3. Train/Test Data
Considering how important the insights taken from the data are to Overfitting/Underfitting (also known as Bias/Variance), it makes sense that there should be something we can do to the data about these.
Now that you have sufficient background, we can compare approaches to train/test data and decide on the best one.
Copyright © 2021 Code 4 Tomorrow. All rights reserved.
The code in this course is licensed under the MIT License.
If you would like to use content from any of our courses, you must obtain our explicit written permission and provide credit. Please contact classes@code4tomorrow.org for inquiries.