Clustering
Clustering is a fundamental step in data analysis, serving the purpose of organizing data into groups or clusters. This process is crucial for identifying patterns, relationships, and outliers within a dataset. By grouping similar data points together, clustering allows for a more comprehensive understanding of the underlying structure of the data.
In the context of clustering, the subsection might delve into specific algorithms, applications, or considerations related to clustering. For instance, hierarchical clustering, DBSCAN (Density-Based Spatial Clustering of Applications with Noise), or discussing when to use different clustering techniques based on data characteristics.
Implementation
The implementation of K-Means clustering involves the following steps:
- Choosing K: Selecting the appropriate number of clusters (K) is crucial. Techniques like the elbow method or silhouette analysis can assist in finding an optimal K value.
- Scaling Data: Before applying clustering algorithms, it's often beneficial to scale or normalize the data, especially if features have different units or scales.
- Initialization Impact: The choice of initial centroids in K-Means can influence the final result. Different initialization methods like k-means++ aim to mitigate this impact.
- Convergence Criteria: Monitoring the change in centroids might not always guarantee convergence. Other criteria, such as the change in cluster assignments or objective function values, can be considered.
- Handling Outliers: K-Means is sensitive to outliers as it tries to minimize the sum of squared distances. Robust clustering techniques or preprocessing steps can be employed to address outliers.
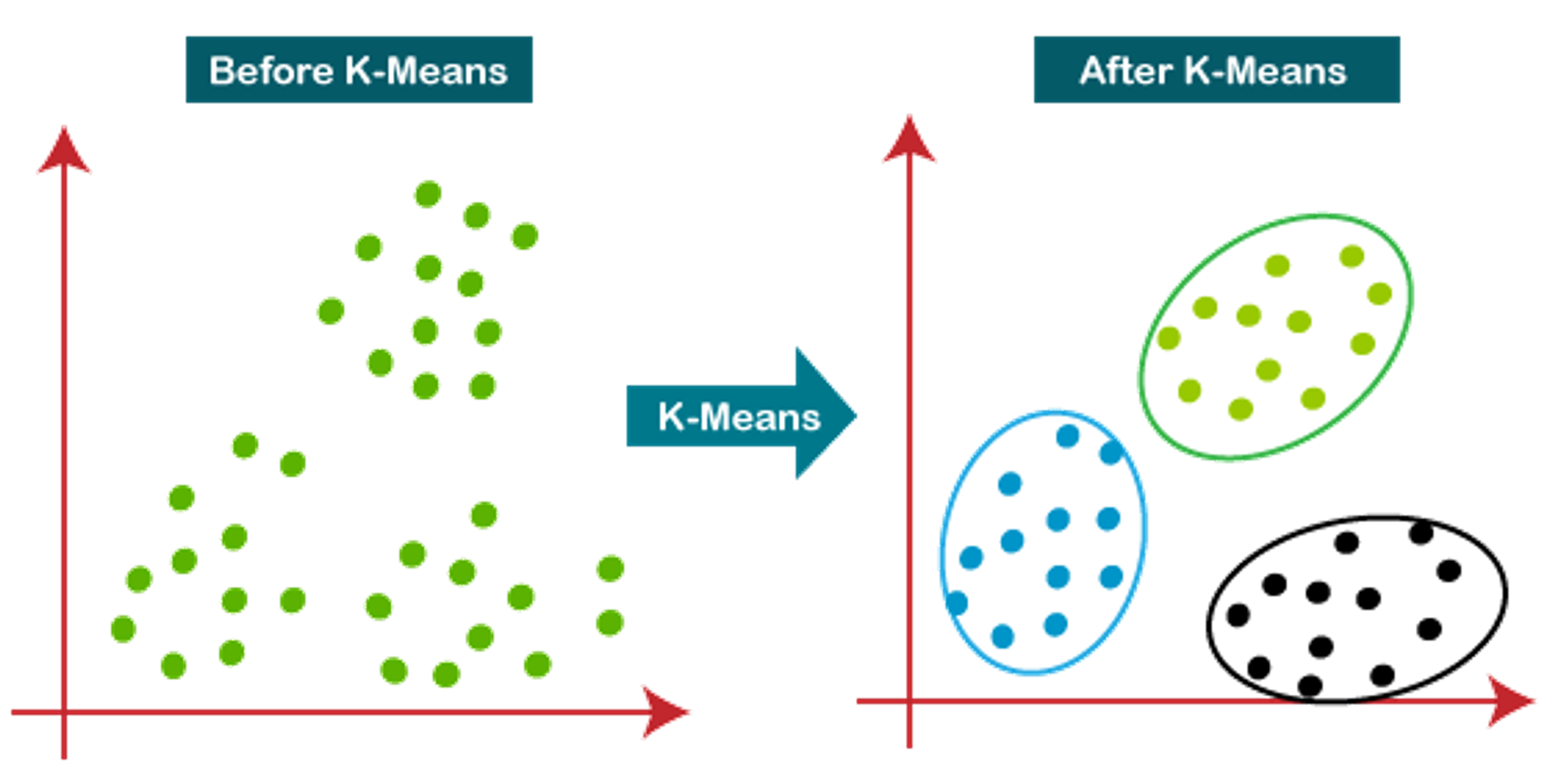
Example:
from sklearn.cluster import KMeans import numpy as np # some random data d = np.array([[1, 2], [5, 8], [1.5, 1.8], [8, 8], [1, 0.6], [9, 11]]) # amount of clusters k = 2 # kmeans modek kmeans = KMeans(n_clusters=k) kmeans.fit(d) # label l = kmeans.labels_ # centroids c = kmeans.cluster_centers_ print("Cluster Labels:", l) print("Centroids:", c)
The Python code demonstrates a basic use of K-Means clustering with the scikit-learn library. It sets up the model, applies it to the data, and provides cluster labels and centroids. This code can be a reference for applying K-Means clustering in real-world situations.
Practice
''' Create a Python script or function that performs K-Means clustering on a given dataset. Define function k_means_clustering(data, k) Implement K-Means algorithm: Initialize centroids randomly Assign data points to nearest centroid Update centroids based cluster means Repeat until convergence or fixed iterations Return cluster_labels and final_centroids Test function on a sample dataset Print cluster labels and final centroids ''' import numpy as np from sklearn.datasets import make_blobs from sklearn.cluster import KMeans # here: def k_means_clustering(data, k): # write the K-Means clustering algorithm here return cluster_labels, final_centroids # create arandom data set data, _ = make_blobs(n_samples=300, centers=3, random_state=42) # test here k = 3 cluster_labels, final_centroids = k_means_clustering(data, k) print("Cluster Labels:", cluster_labels) print("Final Centroids:", final_centroids)
About Me
Create a new class called
AboutMe. In the main method, print your name. On the same line, print any message. On the next line(s), print a stanza from your favorite poem. Make sure it's formatted correctly. And of course, be sure to have good programming style!Add a page link block here (if there is no next section, delete this column)
Copyright © 2021 Code 4 Tomorrow. All rights reserved.
The code in this course is licensed under the MIT License.
If you would like to use content from any of our courses, you must obtain our explicit written permission and provide credit. Please contact classes@code4tomorrow.org for inquiries.